 |
|
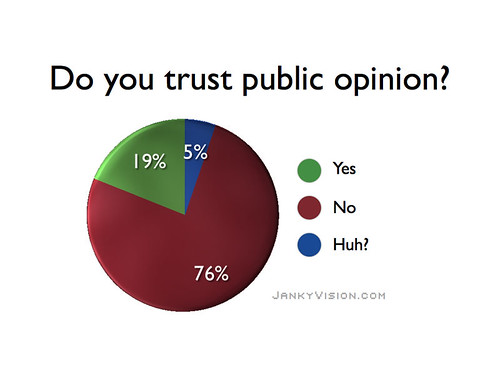
Flickr Photo by Jukebox909 ((Jukebox909, . “Polls show distrust of public opinion.”Flickr. N.p., 16 Nov 2006. Web. 12 May 2010. <http://bit.ly/7Xouzr>.)) |
I have long felt that the greatest value of the social web is in the content that it generates. I suspect that the content’s value compared to the value of “nearly now” ((A term coined by Stephen Heppell)) social idea sharing depends on the person. I’m not a chatter. I procrastinate phone calls. But I love to mine the conversation for ideas, knowledge, and resources that I need right now.
An interesting example of this comes from a Carnegie Mellon University study (pdf) indicating that analyzing data from Twitter posts can yield the same results as conducting a public opinion poll, perhaps costing less and irritating far fewer people.
According to the Mashable blog post I learned this from,
A CMU team from the computer science department looked at sentiments expressed in a billion Twitter messages between 2008 and 2009. The researchers then use simple text analysis methods to filter out updates about the economy and politics and determine if the overall sentiment of the update was positive or negative. The CMU team found that people’s attitudes on consumer confidence and presidential job approval were similar to the results generated by well-reputed, telephone-conducted public opinion polls, such as those conducted by Reuters, Gallup and pollster.com. ((O’Dell, Jolie. “Could Twitter Data Replace Opinion Polls?.”Mashable. 11 May 2010. Web. 12 May 2010. <http://bit.ly/cZa2y8>.))
CMU Assistant Professor Noah Smith thinks that for at least some topics, this kind of passive information gathering could work. Mashable blogger Jolie O’Dell quotes Smith as saying, “With seven million or more messages being tweeted each day, this data stream potentially allows us to take the temperature of the population very quickly.”
Twitter data tends to be noisy, as any tweeter out there knows. But so too is even the most carefully polled data. Researchers learn to filter out the noise, the extraneous data, and round out the results to reveal trends and indicators.
Twitter, as a source for opinion trends, certainly isn’t going to work for just any topic, and the data collected via Twitter tends to fluxuate more on a daily basis than does formally polled data, as discovered by the study. But I often make the point that we will continue to need to refer to authoritative, scientific, and formally vetted information to solve many of our problems. But in a time of rapid change, we need to also develop the skills to cull out timely, experiencial, and community shapped information to answer some of our brand new questions and solve some of our brand new problems.
Added Later: From this, one might say, with an increasingly conversational and participatory web, who needs public opinion polls? Certainly the issues involved are far more complex than that. But I can’t help but wonder if teaching and learning might come to take place in a more networked, digital, and info-abundant environment, and we might continue to develop data mining capabilities, if we might reach the point where the obvious question would be, “Who needs tests?”
David,
I have really missed the opportunity to talk with you in person over the past several years. All seems to be going well for you. I check you out virtually often and weekly listen to your 2centVoice. Thanks. Here is what I consider a piece of news that adds serious dimension to this post …. health care.
http://www.technologyreview.com/biomedicine/25276/?nlid=2970&a=f
I completely agree with you. In our “info-abundant environment” there are a massive number of approaches to teaching and learning with technology. A question I pose is, “Since the technology and applications currently exist, why aren’t we as educators racing to find a means of implementation? What are the obstacles standing in our way when it comes to exploring digital teaching and learning? Is is a lack of funding for equipment/infrastructure? Is is an aging generation of classroom administrators who have an aversion to technology? Is it a lack of training and support for things that are new and may be seen as “radical”?
I certainly feel that one can get a good idea of public opinion through social networking site comments, such as Twitter. However, I do feel that the comments may be a bit biased in that a younger generation typically tweet more frequently than do older adults. So, the opinions may lean more toward the younger generation’s feelings on certain topics and less toward the older generation’s opinions. From an educational standpoint, I think a lot can be said about learning from each other, and social networking sites allow that learning to occur easily. I do feel that educators need to learn about and use technology in the “classroom” in order to reach the most amount of students with different learning styles.
In response to the previous post. I feel that you are correct in saying that the older (mature) generation does not have the same opportunities that the younger generation has. For example, most of my family is on facebook which spearheaded me to join the popular networking site myself; however, my parents are affraid of the technology. I am able to keep in touch with my family and have reunited with many old friends which would be impossible without such a site. Then there is the question “Is it going to remain free?, and how much are you willing to pay for the service?” Many of my colleages use twitter and facebook, is this the new system for nursing education?
I agree in part with what you said regarding bias in polling towards a younger generations view due the younger generation using twitter more, congress would be an exception. I personally have not twittered and I am 50 years old with a graduate degree.I am still in the infancy stages of all the technology of web 2.0. In part I think is due to my own insecurities and fear of the unknown. I have made it this far without it so what am I missing.
I am realizing the importance of the technology and specifically using the web with all it’s glory and the infamous amount of data and sharing and resources that are out there. My hopes of being a nursing educator and enlightening the next generation of nurses I must get on the bandwagon and now. The use of social networking can open up dialogue, share ideas, create interest in educational topics and allow students to interact with their education not just be present. I know I have a learning curve here and I am not totally ignorant of all that technology can do for education I must be the change maker in myself.